

近日,由暨南大学广东智慧教育研究院牵头,联合北京师范大学、华东师范大学、西安交通大学、香港城市大学,依托智慧教育国家新一代人工智能开放创新平台,共同发起的大语言模型在数学能力上的权威测评基准MathEval(官网:https://matheval.ai)正式上线,MathEval是一个专注于全面评估大模型数学能力的测评基准,旨在全面评估大模型在算术、小初高竞赛和部分高等数学分支在内的解题能力表现。

数据显示,截至去年10月,国内累计发布大模型超200个。大模型越来越多地被运用到数学应用领域,包括数学问题解决、数据分析、学术研究、学习辅导等。目前,通用或垂类大模型都具备一定的数学能力,而其能力表现则需要专门测评。不过现有大模型能力测评多数是对通用能力的测评,也有对推理能力、自然科学能力的专门测评中,但没有专门针对数学能力测评的参考基准,以及专门的权威测评机构。
另外,对大模型进行数学能力测评有一些公认的难点:首先,各数据集的字段需要进行统一,每个大模型也都有自己的一套Prompt模板和答案形式,要想给“思维方式”不同的大模型进行统一的测试和比较,需要测评基准根据具体情况,设计符合需求的抽取打分规则,才能从模型输出的内容中批量抽取出可以进一步对比的答案。这对专业能力的要求很高,因为抽取规则的一点点改动,都会影响到最终的测评结果。其次,要让测评榜单的结果具备足够的可参考性,就要使用足够丰富全面的数据集,并尽量全面的测评市面上的大模型,这对测评方的算力也提出了很高的要求。
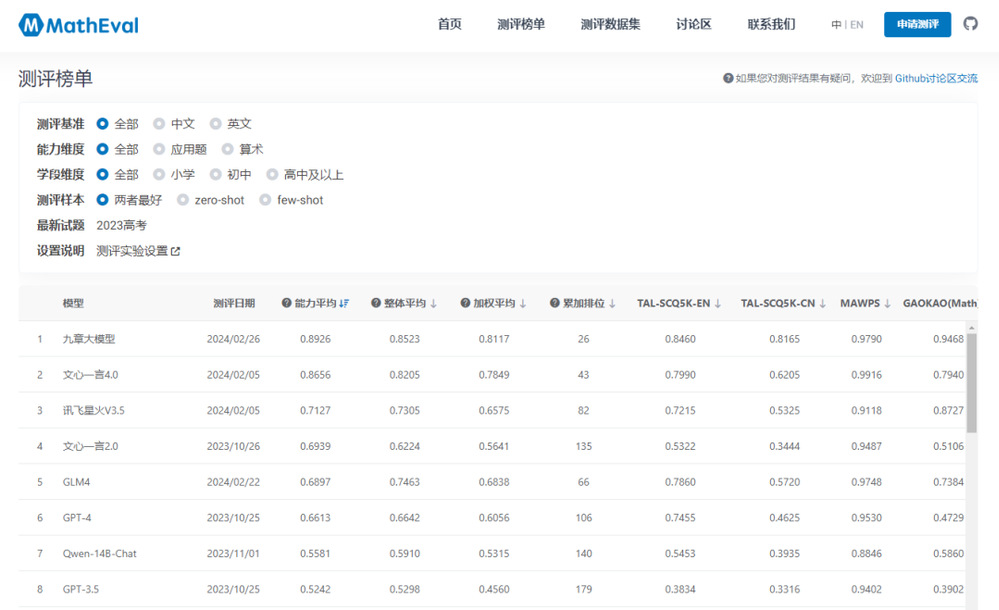
MathEval的上线,弥补了行业空白。截至目前,MathEval收集了2010年以来共19个被广泛使用的数学能力测评数据集,这些数据集来自ACL、AAAI、ICLR等数十个国际人工智能顶会论文中的公开数据,覆盖了不同年级、题型、文本形式和难度的数学问题,从而提供全面、具体的数学能力测评结果。

最新这次测评中,MathEval围绕数学能力,对国内外30个大模型(含同一模型的不同版本)开展测评。在评测过程中,MathEval团队使用了GPT4大模型来进行答案抽取和答案的匹配,减少基于规则进行评测所带来的误差,并根据每个模型的Prompt模板进行了适配,以激发每个模型本身能达到的最佳效果。

结果显示,九章大模型在整体榜单和子榜单均排第一名。同时,作为通用大模型的文心一言4.0、讯飞星火V3.5在测评中的表现也颇为亮眼,占据了第二、三位,均优于GPT-4。由此可见,国产大模型在数学方面的能力已经实现了赶超,未来能力提升和落地应用值得期待。
在这个数字化和智能化日益发展的时代,大语言模型对教育领域的影响越发深刻,其在数学能力的评估和提升上展现出巨大潜力。暨南大学广东智慧教育研究院对其进行了深入研究,致力于挖掘和利用大语言模型相关先进技术,以期为教育的未来发展打开新的可能性。通过与各大学及研究机构的紧密合作,我们不断探索大语言模型在实际教育场景中的应用,力求在培养下一代学习者的过程中,实现技术与教育的完美融合。我们坚信,这些研究将为教育行业带来革命性的变革,并有望在全球范围内推动智慧教育的新浪潮。
